Today, a change to our Tiered Cache system caused some requests to fail for users with status code 530. The impact lasted for almost six hours in total. We estimate that about 5% of all requests failed at peak. Because of the complexity of our system and a blind spot in our tests, we did not spot this when the change was released to our test environment.
The failures were caused by side effects of how we handle cacheable requests across locations. At first glance, the errors looked like they were caused by a different system that had started a release some time before. It took our teams a number of tries to identify exactly what was causing the problems. Once identified we expedited a rollback which completed in 87 minutes.
We’re sorry, and we’re taking steps to make sure this does not happen again.
Background
One of Cloudflare’s products is our Content Delivery Network, or CDN. This is used to cache assets for websites globally. However, a data center is not guaranteed to have an asset cached. It could be new, expired, or has been purged. If that happens, and a user requests that asset, our CDN needs to retrieve a fresh copy from a website’s origin server. But the data center that the user is accessing might still be pretty far away from the origin server. This presents an additional issue for customers: every time an asset is not cached in the data center, we need to retrieve a new copy from the origin server.
To improve cache hit ratios, we introduced Tiered Cache. With Tiered Cache, we organize our data centers in the CDN into a hierarchy of “lower tiers” which are closer to the end users and “upper tiers” that are closer to the origin. When a cache-miss occurs in a lower tier, the upper tier is checked. If the upper tier has a fresh copy of the asset, we can serve that in response to the request. This improves performance and reduces the amount of times that Cloudflare has to reach out to an origin server to retrieve assets that are not cached in lower tier data centers.
Incident timeline and impact
At 08:40 UTC, a software release of a CDN component containing a bug began slowly rolling out. The bug was triggered when a user visited a site with either Tiered Cache, Cloudflare Images, or Bandwidth Alliance configured. This bug caused a subset of those customers to return HTTP Status Code 530 — an error. Content that could be served directly from a data center’s local cache was unaffected.
We started an investigation after receiving customer reports of an intermittent increase in 530s after the faulty component was released to a subset of data centers.
Once the release started rolling out globally to the remaining data centers, a sharp increase in 530s triggered alerts along with more customer reports, and an incident was declared.
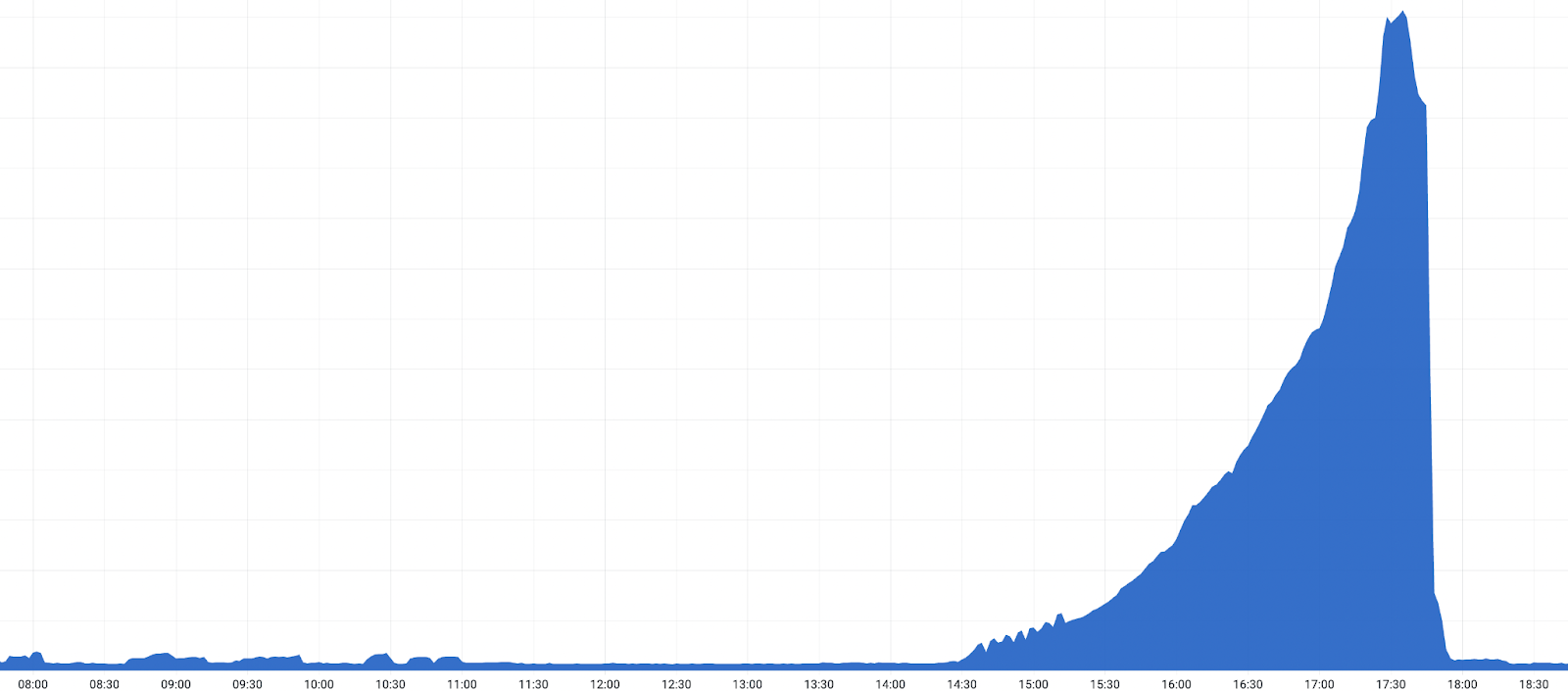
We confirmed a bad release was responsible by rolling back the release in a data center at 17:03 UTC. After the rollback, we observed a drop in 530 errors. After this confirmation, an accelerated global rollback began and the 530s started to decrease. Impact ended once the release was reverted in all data centers configured as Tiered Cache upper tiers at 18:04 UTC.
Timeline:
- 2022-10-25 08:40: The release started to roll out to a small subset of data centers.
- 2022-10-25 10:35: An individual customer alert fires, indicating an increase in 500 error codes.
- 2022-10-25 11:20: After an investigation, a single small data center is pinpointed as the source of the issue and removed from production while teams investigate the issue there.
- 2022-10-25 12:30: Issue begins spreading more broadly as more data centers get the code changes.
- 2022-10-25 14:22: 530s errors increase as the release starts to slowly roll out to our largest data centers.
- 2022-10-25 14:39: Multiple teams become involved in the investigation as more customers start reporting increases in errors.
- 2022-10-25 17:03: CDN Release is rolled back in Atlanta and root cause is confirmed.
- 2022-10-25 17:28: Peak impact with approximately 5% of all HTTP requests resulting in an error with status code 530.
- 2022-10-25 17:38: An accelerated rollback continues with large data centers acting as Upper tier for many customers.
- 2022-10-25 18:04: Rollback is complete in all Upper Tiers.
- 2022-10-25 18:30: Rollback is complete.
During the early phases of the investigation, the indicators were that this was a problem with our internal DNS system that also had a release rolling out at the same time. As the following section shows, that was a side effect rather than the cause of the outage.
Adding distributed tracing to Tiered Cache introduced the problem
In order to help improve our performance, we routinely add monitoring code to various parts of our services. Monitoring code helps by giving us visibility into how various components are performing, allowing us to determine bottlenecks that we can improve on. Our team recently added additional distributed tracing to our Tiered Cache logic. The tiered cache entrypoint code is as follows:
* Before:
function _M.go()
-- code to run here
end
* After:
local trace_fn = require("opentracing").trace_fn
local function go()
-- code to run here
end
function _M.go()
trace_fn(ngx.ctx, "tiered_cache_rewrite", go)
endThe code above wraps the existing go() function with trace_fn() which will call the go() function and then reports its execution time.
However, the logic that injects a function to the opentracing module clears control headers on every request:
require("opentracing").configure_module(conf,
-- control header extractor
function(ctx)
-- Always clear the headers.
clear_control_headers()
-- Normally, we extract data from these control headers before clearing them as a routine part of how we process requests.
But internal tiered cache traffic expects the control headers from the lower tier to be passed as-is. The combination of clearing headers and using an upper tier meant that information that might be critical to the routing of the request was not available. In the subset of requests affected, we were missing the hostname to resolve by our internal DNS lookup for origin server IP addresses. As a result, a 530 DNS error was returned to the client.
Remediation and follow-up steps
To prevent this from happening again, in addition to the fixing the bug, we have identified a set of changes that help us detect and prevent issues like this in the future:
- Include a larger data center that is configured as a Tiered Cache upper tier in an earlier stage in the release plan. This will allow us to notice similar issues more quickly, before a global release.
- Expand our acceptance test coverage to include a broader set of configurations, including various Tiered Cache topologies.
- Alert more aggressively in situations where we do not have full context on requests, and need the extra host information in the control headers.
- Ensure that our system correctly fails fast in an error like this, which would have helped identify the problem during development and test.
Conclusion
We experienced an incident that affected a significant set of customers using Tiered Cache. After identifying the faulty component, we were able to quickly rollback and remediate the issue. We are sorry for any disruption this has caused our customers and end users trying to access services.
Remediations to prevent such an incident from happening in the future will be put in place as soon as possible.